View or edit on GitHub
This page is synchronized from trase/data/brazil/beef/ciff/EXPORT_CIFF_FARM_SIZE_DATA.md. Last modified on 2026-03-21 22:30 CET by Trase Admin.
Please view or edit the original file there; changes should be reflected here after a midnight build (CET time),
or manually triggering it with a GitHub action (link).
Export slaughterhouse size data for supply shed comparison
Erasmus 2025-05-23
This script exports the size (slaughter tonnes/year) of 35 slaughterhouses used in the supply shed methods comparison as part of the CIFF project.
It takes the slaughterhouse list, filters to the relevant facilities, adds in data on their slaughter (number of heads/year), and then adds in data on carcass weights to calculate the slaughter tonnes/facility/year.
The data are exported to
brazil/beef/ciff/supply_shed_reviews/in/SLAUGHTERHOUSE_SIZE.csv.
# String cleaning function
str_trans <- function(x) {
x %>%
stringi::stri_trans_toupper() %>%
stringi::stri_trans_general("Latin-ASCII")
}
# Load state names/codes
state_dic <-
s3read_using(
object = "brazil/metadata/state_dictionary.csv",
FUN = read_delim,
delim = ";",
col_types = cols(TWO_DIGIT_CODE = col_character()),
bucket = ts,
opts = c("check_region" = T)
)
Load data
# Load beef logistic hubs
# ... we use the v3 of these data, to mirror the dpap script:
# dpap repo: `scripts/DATA/SLAUGHTER/ESTIMATE_SLAUGHTERHOUSE_SIZE.md`
# ... where we also manipulate the slaughter volume data
lhv3 <-
s3read_using(
object = "brazil/logistics/slaughterhouses/slaughterhouse_map_v3/2022-06-09-br_beef_logistics_map_v3.csv",
delim = ";",
FUN = read_delim,
col_types = cols(CNPJ = col_character(),
GEOCODE = col_character(),
INSPECTION_NUM = col_character()),
opts = c("check_region" = T),
bucket = ts
)
# Filter to the relevant slaughterhouses
ids <- c(
"SIF_68067446001572_4150_1",
"SIE_09403639000192_26_1",
"SIF_04749233000223_101_1",
"SIF_11831785000241_4554_1",
"SIE_12152699000194_60_1",
"SIF_09248966000117_2258_1",
"SIF_02916265013652_1110_1",
"SIF_11831785000322_4413_1",
"SIF_03721769000944_2437_1",
"SIF_02916265013814_2350_1",
"SIF_11610856000286_4686_1",
"SIF_02916265013733_807_1",
"SIF_04749233000142_112_1",
"SIF_25264597000374_4398_1",
"SIE_34899773000173_16_1",
"SIF_68067446001068_2583_1",
"SIF_08915713000197_1891_1",
"SIE_09002615000121_62_1",
"SIF_02916265014110_457_1",
"SIF_06128996000100_2801_1",
"SIE_07843933000190_17_1",
"SIE_16659907000105_5_1",
"SIE_05705970000106_53_1",
"SIE_36479742000199_86_1",
"SIF_10748137000182_372_1",
"SIE_11753119000151_11_1",
"SIE_11248016000134_76_1",
"SIE_05339106000138_77_1",
"SIF_01535759000131_1367_1",
"SIF_08312400000144_2927_1",
"SIE_24773708000143_66_1",
"SIE_30356337000105_11122021_1",
"SIE_22956064000101_34_1",
"SIE_02044870000198_10_1",
"SIE_27531099000104_74_1"
)
relevant_shs <- lhv3 %>% filter(UNI_ID %in% ids)
stopifnot(nrow(relevant_shs) == length(ids))
# Load the raw slaughterhouse size data
# ... as produced in the dpap repo: `scripts/DATA/SLAUGHTER/ESTIMATE_SLAUGHTERHOUSE_SIZE.md`
path <- "data/SLAUGHTER/slaughterhouse_sizes/"
keys <- map_chr(get_bucket("trase-app", prefix = path), "Key")
states <- str_sub(sub(".*sizes/", "", keys), start = 1, end = 2)
res <- map(
.x = keys,
.f = ~ s3read_using(object = .x, bucket = "trase-app", FUN = read_delim, delim = ";")
)
names(res) <- states
Visualise slaughterhouse size data
# Visualise the size of each slaughterhouse, based on 2017/2018 data (where we had many GTA)
bind_rows(res, .id = "STATE") %>%
filter(DESTINATION_TAX_NUMBER %in% relevant_shs$CNPJ) %>%
mutate(WHO = paste0(COMPANY, "\n", DESTINATION_TAX_NUMBER)) %>%
ggplot(aes(WHO, NUM_CATTLE, col = as.character(TRANSPORT_YEAR))) +
facet_grid(rows = vars(INSPECTION_LEVEL), scales = "free", space = "free") +
geom_point() +
theme_classic() +
coord_flip() +
theme(axis.title.y = element_blank(),
legend.title = element_blank())
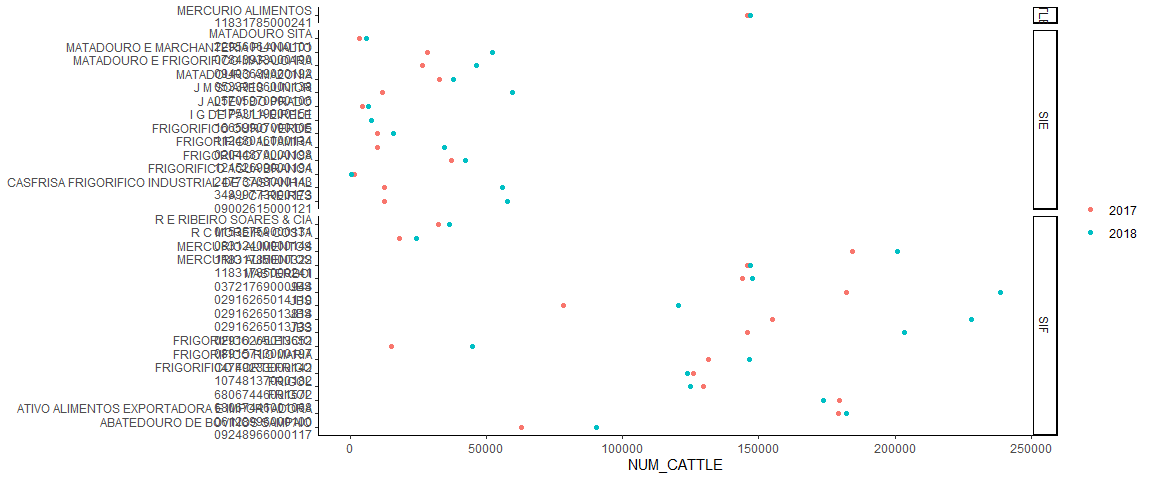
We’ll use the mean size per slaughterhouse across the years - nb what is the variation per slaughterhouse?
# Make a df of the slaughterhouse sizes
shs_sizes <- bind_rows(res, .id = "STATE") %>%
right_join(relevant_shs, by = c("DESTINATION_TAX_NUMBER" = "CNPJ", "INSPECTION_LEVEL", "STATUS", "STATE")) %>%
select(UNI_ID, COMPANY = COMPANY.y, CNPJ = DESTINATION_TAX_NUMBER, INSPECTION_LEVEL, STATE, LONG, LAT, STATUS, NUM_CATTLE) %>%
filter(CNPJ %in% relevant_shs$CNPJ) %>%
group_by(UNI_ID, COMPANY, CNPJ, INSPECTION_LEVEL, LONG, LAT, STATE, STATUS) %>%
summarise(MEAN_NUM_HEADS = mean(NUM_CATTLE),
PERC_VAR_NUM_HEADS = (max(NUM_CATTLE) - min(NUM_CATTLE)) / max(NUM_CATTLE) * 100) %>%
ungroup()
# Display the % difference in slaughtered heads per slaughterhouse, between years
shs_sizes %>% pull(PERC_VAR_NUM_HEADS) %>% summary()
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.8796 8.1012 28.4750 31.1210 45.9192 80.3445 6
A mean variation of 31.1209466%, median of 28.4750192%, and standard deviation of 26.8593167%
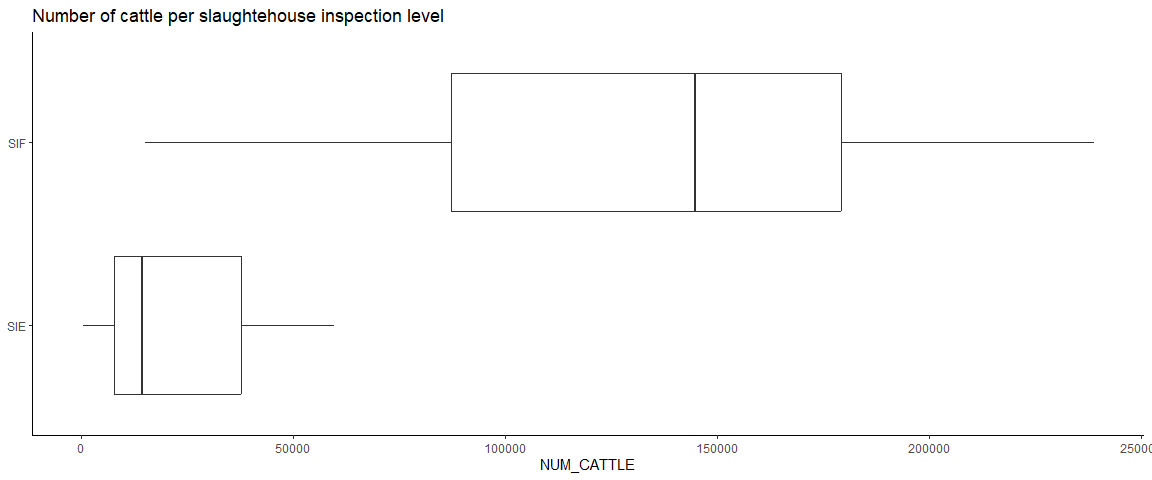
For the 6 slaughterhouses where we didn’t have GTA data (to estiamte slaughter volumes), we use the mean slaughterhouse volume per inspection level (SIF, SIE, SIM):
bind_rows(res, .id = "STATE") %>%
right_join(relevant_shs, by = c("DESTINATION_TAX_NUMBER" = "CNPJ", "INSPECTION_LEVEL", "STATUS")) %>%
filter(DESTINATION_TAX_NUMBER %in% relevant_shs$CNPJ) %>%
ggplot(aes(INSPECTION_LEVEL, NUM_CATTLE)) +
geom_boxplot() +
theme_classic() +
coord_flip() +
theme(axis.title.y = element_blank(),
legend.title = element_blank()) +
labs(title = "Number of cattle per slaughtehouse inspection level")
mean_sizes <- bind_rows(res, .id = "STATE") %>%
right_join(relevant_shs, by = c("DESTINATION_TAX_NUMBER" = "CNPJ", "INSPECTION_LEVEL", "STATUS", "STATE")) %>%
filter(DESTINATION_TAX_NUMBER %in% relevant_shs$CNPJ) %>%
group_by(INSPECTION_LEVEL, STATE) %>%
summarise(MEAN_NUM_HEADS = mean(NUM_CATTLE, na.rm = T)) %>%
ungroup()
These sizes are:
mean_sizes
## # A tibble: 2 × 3
## INSPECTION_LEVEL STATE MEAN_NUM_HEADS
## <chr> <chr> <dbl>
## 1 SIE PA 23921.
## 2 SIF PA 129455.
# Add the missing slaughter volume data
shs_sizes2 <- left_join(shs_sizes, mean_sizes, by = c("INSPECTION_LEVEL", "STATE")) %>%
mutate(MEAN_NUM_HEADS = coalesce(MEAN_NUM_HEADS.x, MEAN_NUM_HEADS.y)) %>%
select(-MEAN_NUM_HEADS.x, -MEAN_NUM_HEADS.y)
stopifnot(any(is.na(shs_sizes2$MEAN_NUM_HEADS)) == FALSE)
Add carcass weights
# Load slaughter data
abate_bov <- s3read_using(
object = paste0("data/ABATE/2024-03-14-CATTLE_TRIMESTRAL_SURVEY.csv"),
bucket = "trase-app",
FUN = read_delim,
delim = ";"
)
# Rename columns
abate_bov <-
abate_bov %>%
mutate(SPECIES = "BOV") %>%
filter(`Tipo de rebanho bovino` == "Total") %>%
select(SPECIES,
STATE_CODE = `Unidade da Federação (Código)`,
STATE = `Unidade da Federação`,
TIME_PERIOD = `Trimestre`,
DATA_TYPE = `Variável`,
TIME = `Referência temporal`,
INSPECTION_LEVEL = `Tipo de inspeção`,
UNITS = `Unidade de Medida`,
NUMBER = Valor) %>%
mutate_if(is.character, str_to_upper) %>%
mutate(STATE_CODE = as.character(STATE_CODE))
# Aggregate slaughter numbers per species/state/year
carcass_weights <-
abate_bov %>%
filter(INSPECTION_LEVEL == "TOTAL",
TIME == "TOTAL DO TRIMESTRE") %>%
mutate(UNITS = str_trans(UNITS)) %>%
mutate(TRANSPORT_YEAR = str_sub(TIME_PERIOD, start = -4, end = -1),
TRANSPORT_YEAR = as.numeric(TRANSPORT_YEAR),
NUMBER = ifelse(NUMBER %in% c("X", "-", "..."), "0", NUMBER),
NUMBER = as.numeric(NUMBER)) %>%
filter(UNITS != "UNIDADES") %>%
group_by(STATE_CODE, TRANSPORT_YEAR, UNITS) %>%
summarise(NUMBER = sum(NUMBER, na.rm = T)) %>%
ungroup() %>%
left_join(state_dic, by = c("STATE_CODE" = "TWO_DIGIT_CODE")) %>%
pivot_wider(names_from = UNITS, values_from = NUMBER) %>%
mutate(CARCASS_WEIGHT_TONNES = QUILOGRAMAS / 1000 / CABECAS)
# Take a mean per state
carcass_weights_mean <- carcass_weights %>%
group_by(STATE_ABBR) %>%
summarise(MEAN_CARCASS_WEIGHT_TONNES = mean(CARCASS_WEIGHT_TONNES)) %>%
ungroup()
# Join the carcass data to the slaughter heads
# ... and calculate slaughter weight per slaughterhouse per year
shs_sizes3 <- left_join(shs_sizes2, carcass_weights_mean, by = c("STATE" = "STATE_ABBR")) %>%
mutate(SLAUGHTERED_CARCASS_TONNES = MEAN_NUM_HEADS * MEAN_CARCASS_WEIGHT_TONNES)
The carcass weight data used is the mean weight (kg per carcass) per state, using data from the IBGE pesquisa trimestral for the years 2016- 2022.
These mean weights are:
as.data.frame(carcass_weights_mean)
## STATE_ABBR MEAN_CARCASS_WEIGHT_TONNES
## 1 AC 0.2400989
## 2 AL 0.2483527
## 3 AM 0.2229132
## 4 AP NaN
## 5 BA 0.2566633
## 6 CE 0.1998655
## 7 DF NaN
## 8 ES 0.2529066
## 9 GO 0.2636155
## 10 MA 0.2454972
## 11 MG 0.2490160
## 12 MS 0.2570998
## 13 MT 0.2742674
## 14 PA 0.2578360
## 15 PB 0.2582843
## 16 PE 0.2523933
## 17 PI 0.1871244
## 18 PR 0.2469931
## 19 RJ 0.2262501
## 20 RN 0.2078053
## 21 RO 0.2549324
## 22 RR 0.2392747
## 23 RS 0.2238535
## 24 SC 0.2285777
## 25 SE NaN
## 26 SP 0.2739292
## 27 TO 0.2620355
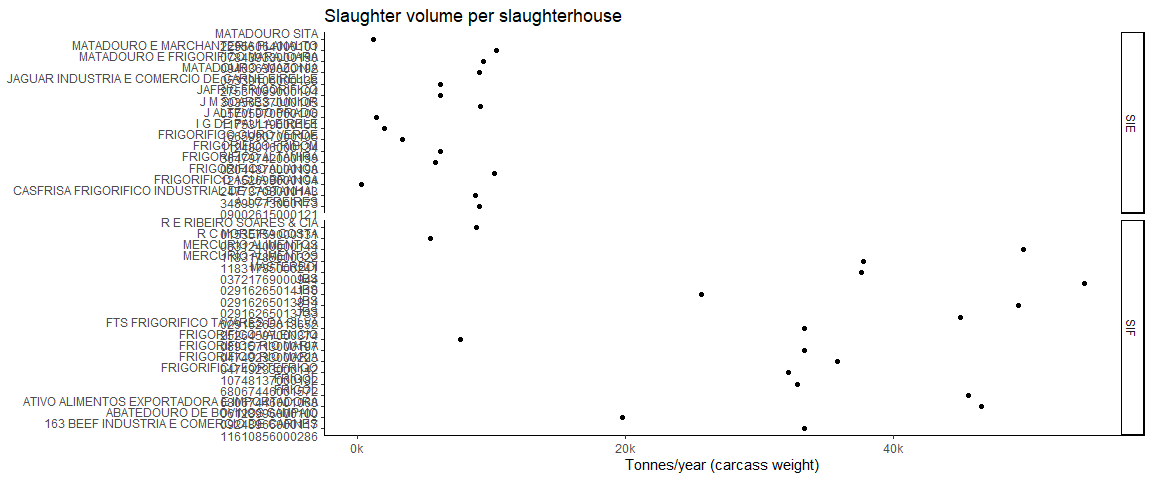
shs_sizes3 %>%
mutate(WHO = paste0(COMPANY, "\n", CNPJ)) %>%
ggplot(aes(WHO, SLAUGHTERED_CARCASS_TONNES)) +
facet_grid(rows = vars(INSPECTION_LEVEL), scales = "free", space = "free") +
geom_point() +
theme_classic() +
coord_flip() +
theme(axis.title.y = element_blank(),
legend.title = element_blank()) +
scale_y_continuous(label = unit_format(unit = "k", scale = 1e-3, sep = "")) +
labs(title = "Slaughter volume per slaughterhouse",
y = "Tonnes/year (carcass weight)")
Export
# Export the slaughterhouse size data
shs_sizes3 %>%
select(UNI_ID, COMPANY, CNPJ, INSPECTION_LEVEL, LONG, LAT, STATE, SLAUGHTERED_CARCASS_TONNES) %>%
s3write_using(
x = .,
object = "brazil/beef/ciff/supply_shed_reviews/in/SLAUGHTERHOUSE_SIZE.csv",
FUN = write_delim,
delim = ";",
bucket = ts
)